Wie ist es möglich, dass auf einer Diskstation aus dem Jahr 2012 mit nur 4 GB verbautem Arbeitsspeicher ein Volumen von 200 TB erstellt werden kann, während heutige Synology NAS-Systeme dafür anscheinend mindestens 32 GB RAM benötigen?
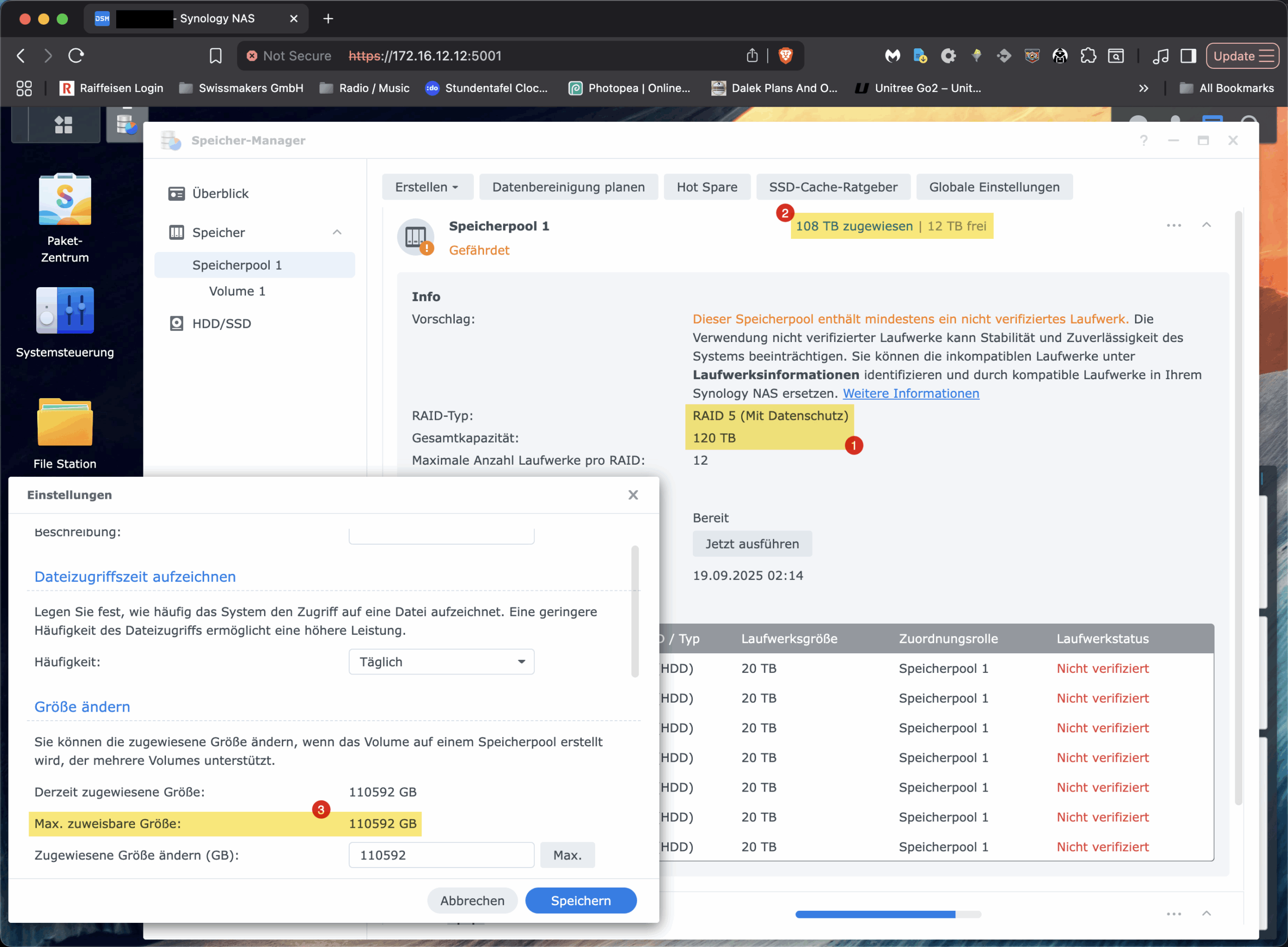
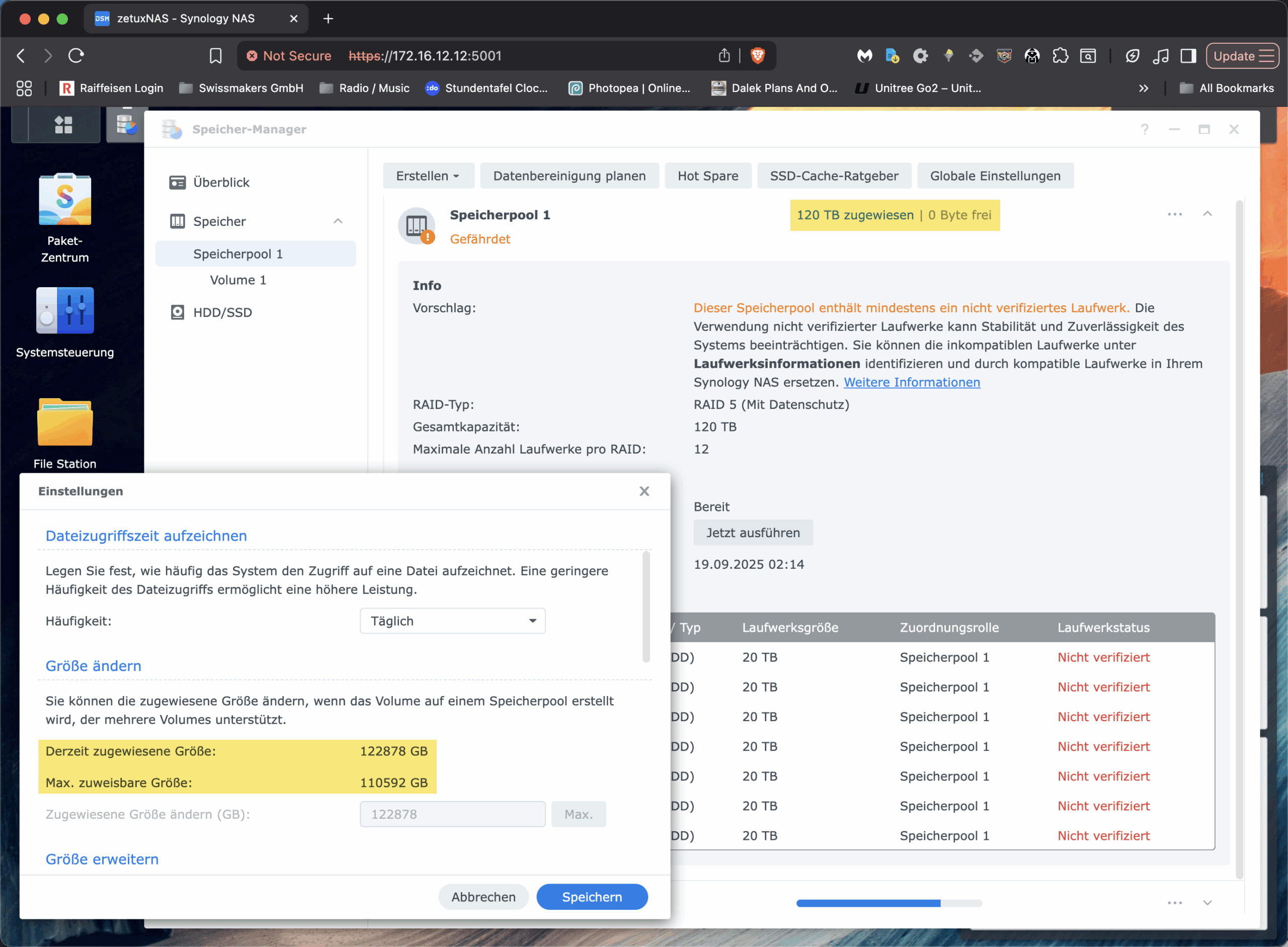
Vor dieser Frage stand ich kürzlich, als wir bei einer unserer Installationen von Swissmakers vor einem vertrauten, aber irritierenden Phänomen standen: Ein Synology-NAS mit sieben 22-TB-HDDs im RAID-5 zeigte im Speicherpool korrekt rund «120 TB» an (1), liess aber das vorhandene Volume partout nicht über ca. 108 TB vergrössern (2/3). Die Oberfläche bot keine Option, obwohl der Pool noch freie Kapazität hatte. Für alle, die ähnliches beobachten und in dem GUI gegen eine unsichtbare Decke laufen: Das ist kein technologisches Limit von Btrfs oder LVM und hat auch nichts mit der RAM-Bestückung zu tun. Es ist eine modellabhängige Software-Schranke in der DSM-Oberfläche. In diesem Beitrag zeige ich, warum das so ist und wie man das Synology Volume trotzdem sauber und online per CLI über diese Grenze hinaus erweitert.
Die Fakten
Beginnen wir mit den Zahlen. Festplattenhersteller rechnen dezimal: 1 TB sind 10¹² Byte. Betriebssysteme und auch das DSM rechnen binär: 1 TiB sind 2⁴⁰ Byte. Eine 22-TB-Platte entspricht also real etwa 20,0 TiB. Sieben dieser Laufwerke in RAID-5 ergeben brutto ungefähr 140 TiB; eine Platte fällt für Parität weg, netto bleiben rund 120 TiB im Pool. An dieser Stelle ist noch alles stimmig. Der Stolperstein entsteht später, auf der Ebene des Volumes.
Synology organisiert sein System so: Zuunterst läuft ein mdadm-RAID, darauf liegt ein LVM mit einer Volume Group (bei vielen Geräten „vg1“ genannt), und darauf wiederum das eigentliche Dateisystem, in unserem Fall Btrfs. DSM trennt bewusst zwischen Speicherpool und Volume. Der Pool repräsentiert die physische Kapazität des RAID-Sets; Volumes sind LVM-Logical-Volumes, denen man via GUI Kapazität aus dem Pool zuweist. Und genau hier besitzt DSM eine modellabhängige Obergrenze für die Grösse eines einzelnen Volumes, die bei zahlreichen Plus-Modellen und anderen Modellen bei 108 TiB liegt. Das ist keine technische Notwendigkeit von LVM oder Btrfs, sondern eine durch Synology bewusst platzierte Software-Schranke in der Oberfläche. Der Beleg dafür ist trivial: Der Pool zeigt freie Extents und LVM kann sie an das bestehende LV hängen; danach lässt sich das Btrfs online resizen, vollständig ohne Umformatieren, Downtime oder sonstige «magische» Schritte.
Btrfs selbst ist in dieser Konstellation nicht der limitierende Faktor. Das Dateisystem unterstützt Online-Resize, ist chunk-basiert aufgebaut und verwaltet Daten und Metadaten in getrennten Bereichen. Es skaliert auf Kapazitäten weit oberhalb dessen, was eine 7-Bay-Konfiguration überhaupt liefern kann. Auch die block-device-Geschichte ist mit LVM unkritisch: Solange die VG freie Extents hat, lässt sich das LV vergrössern. Weder die CPU-Architektur eines Plus-Modells noch die RAM-Ausstattung bestimmen hart die maximal adressierbare Grösse eines Btrfs-Volumes. Mehr RAM hilft Caches und damit der Performance, aber es ändert nichts an den Adressbreiten der beteiligten Schichten. Wer also in der DSM-Maske bei «Max. zuweisbare Grösse 110 592 GB» hängenbleibt, stösst auf eine UI-Einschränkung, nicht aber auf eine technisch bedingte Grenze.
Die Lösung dazu
Die Lösung liegt im Werkzeugkasten, den wir als Linux-Ingenieure ohnehin täglich benutzen: Wir erweitern das Logical Volume mit LVM und ziehen das Btrfs anschliessend nach. Dabei bleibt das System im Betrieb; Services, Freigaben und NFS/SMB-Clients arbeiten weiter. Der Ablauf ist bei jedem UNIX-basierten System, welches LVM einsetzt, gleich: zunächst den Ist-Zustand zweifelsfrei verifizieren, das LV vergrössern, und zum Schluss das Dateisystem auf 100% der Grösse des LVs resizen. Ich werden gleich die konkreten Kommandos alle niederschreiben, damit man die einzelnen Schritte direkt auch in die eigene Umgebung durchführen kann.
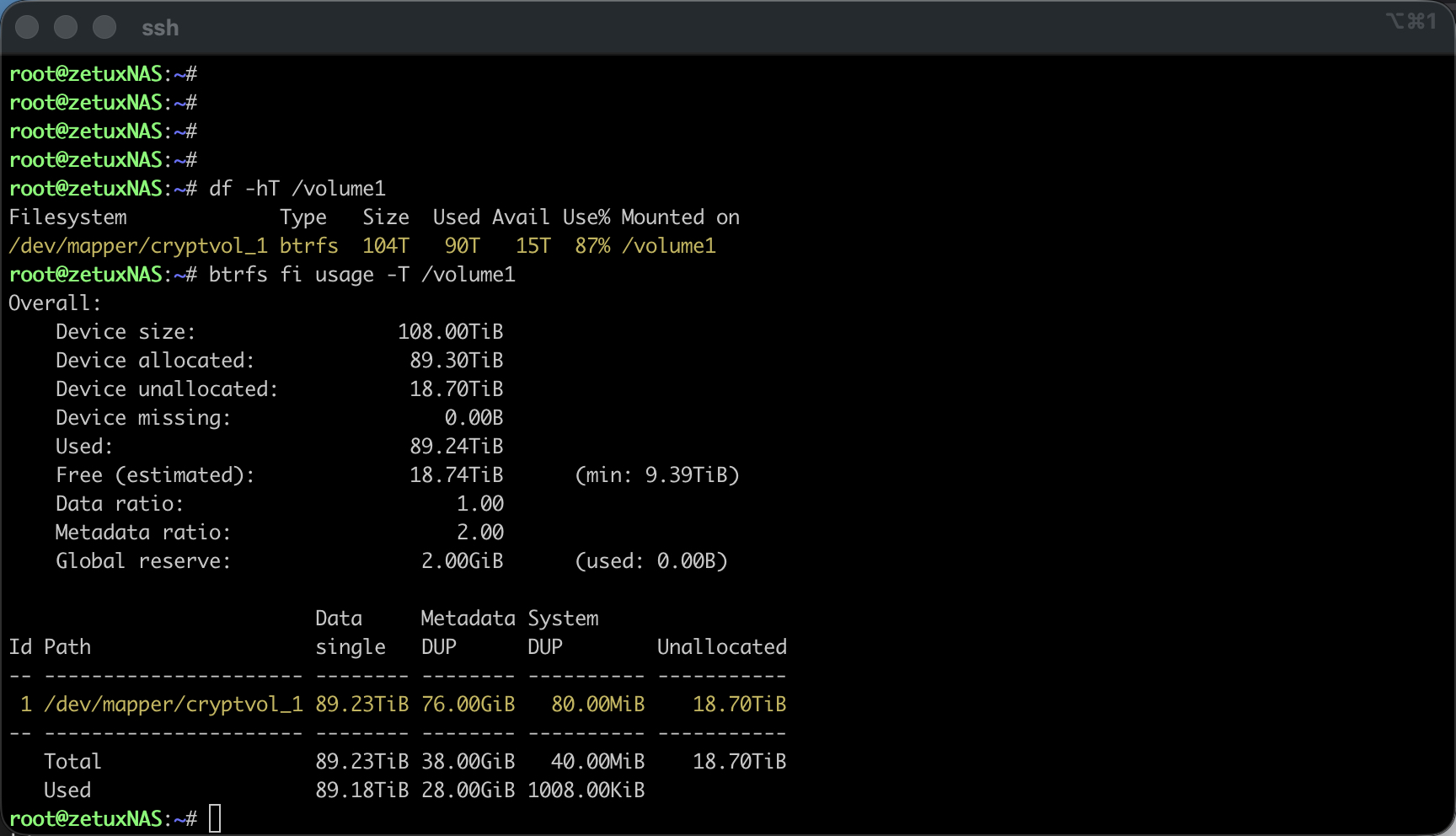
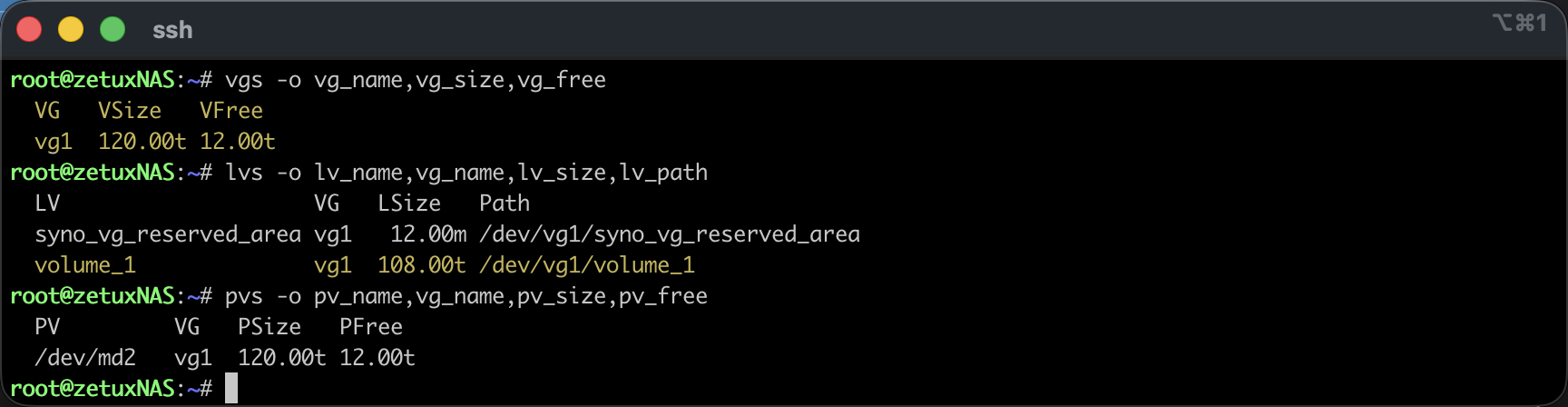
Zuerst wähle ich den sicheren Einstieg per SSH und eskaliere auf root (Wie das genau gemacht werden kann, wurde bereits hier beschrieben: Link). Danach prüfe ich die beteiligten Storage-Schichten.# df -hT /volume1 bestätigt das Dateisystem und den Mountpunkt, # mount | grep volume1 zeigt die tatsächliche Gerätedatei, die bei Synology in der Regel bei verschlüsselten Volumen über den Mapper als /dev/mapper/cryptvol_1 eingebunden ist. Mit # vgs -o vg_name,vg_size,vg_free,# lvs -o lv_name,vg_name,lv_size,lv_path und # pvs -o pv_name,vg_name,pv_size,pv_free verschaffe ich mir Klarheit, wie die Volume Group heisst, welche Logical Volumes existieren und wie viele freie Extents im Pool tatsächlich anliegen. An dieser Stelle sollte «VFree» eine Grössenordnung um die in der GUI angezeigten 12 TB, «12.00t» frei zeigen; entscheidend ist ausserdem der exakte lv_path, meist /dev/vg1/volume_1.
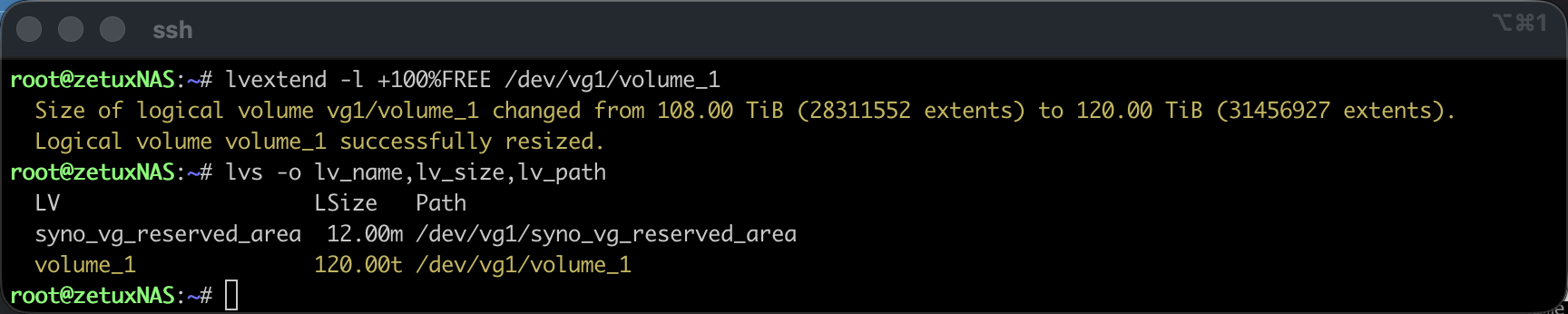
Ist die Ausgangslage eindeutig, kann das LV erweitert werden. Dazu genügt ein einzelner Aufruf, der alle freien Extents der VG an das Ziel-LV hängt. Mit einer Pfadangabe aus der lvs-Ausgabe sieht das so aus:
lvextend -l +100%FREE /dev/vg1/volume_1Die Option -l arbeitet mit Extents und ist in dieser Situation robuster als eine genaue Grössenangabe in Bytes; sie konsumiert in Kombination mit 100% exakt den freien Bereich der VG, unabhängig von Rundungen. Ein unmittelbar folgendes # lvs -o lv_name,lv_size,lv_path zeigt die neue LV-Grösse. Bis hierher hat sich am Dateisystem noch nichts geändert, wir haben lediglich die Blockdevice-Schicht erweitert.
Reboot (Empfohlen)
Ein Reboot ist nicht in allen Fällen nötig, jedoch falls das Volume1 zusätzlich verschlüsselt wurde, oder das Synology den Einbau eines Caches unterstützt, so muss noch vor dem btrfs resize das dm-crypt/LUKS-Device (cryptvol_1) als sowohl das darunter liegende cachedev_0 auf die neue LV-Grösse vergrössert werden. Eine kurze Kontrolle erfolgt anhand: # dmsetup ls --tree
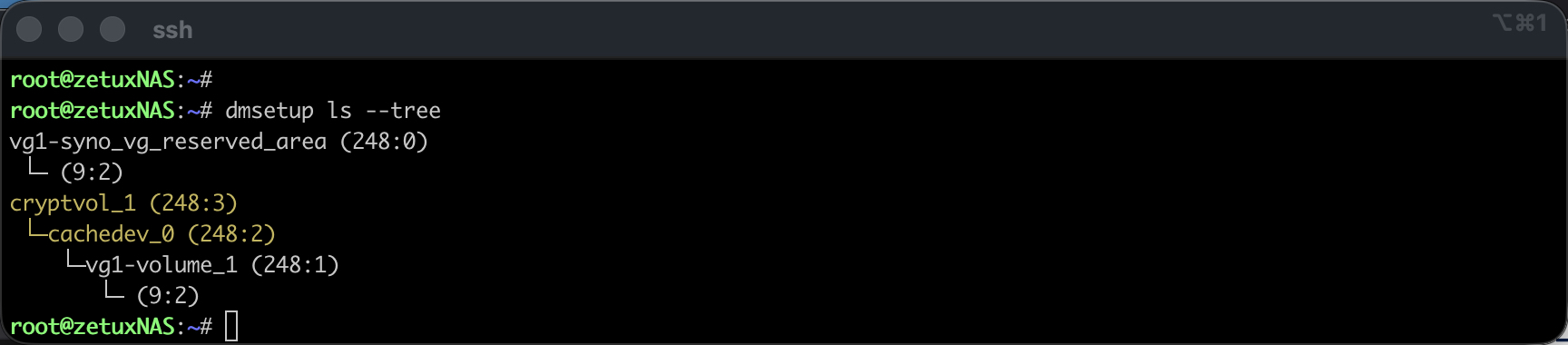
Wird eines oder beide der genannten virtuellen Devices angezeigt, so empfielt sich ein reboot. Um cachedev_0 als sowohl cryptvol_1 alternativ online zu vergrössern kann folgendermassen vorgegangen werden: (Ohne Reboot – jedoch nicht ohne Risiko)
# Aktuelle Sektorgrösse von cachedev_0 abfragen:
dmsetup table --showkeys cachedev_0
# Neue Sektorgrösse vom LV holen:
SECTORS=$(blockdev --getsz /dev/vg1/volume_1)
# cachedev_0 suspenden, cachedev_0 Table mit neuer Länge reloaden und reaktivieren:
dmsetup suspend cachedev_0
dmsetup table --showkeys cachedev_0 \
| sed '/^Size Hist:/,$d' \
| awk -v S="$SECTORS" 'NR==1{$2=S} {print}' OFS=" " \
| dmsetup reload cachedev_0 --table -
dmsetup resume cachedev_0
# Falls vorhanden LUKS/dm-crypt auf neue Grösse von cachedev_0 resizen:
cryptsetup resize cryptvol_1
# Prüfen ob cachedev_0 (und cryptvol_1) erfolgreich resized wurden:
dmsetup table --showkeys cachedev_0
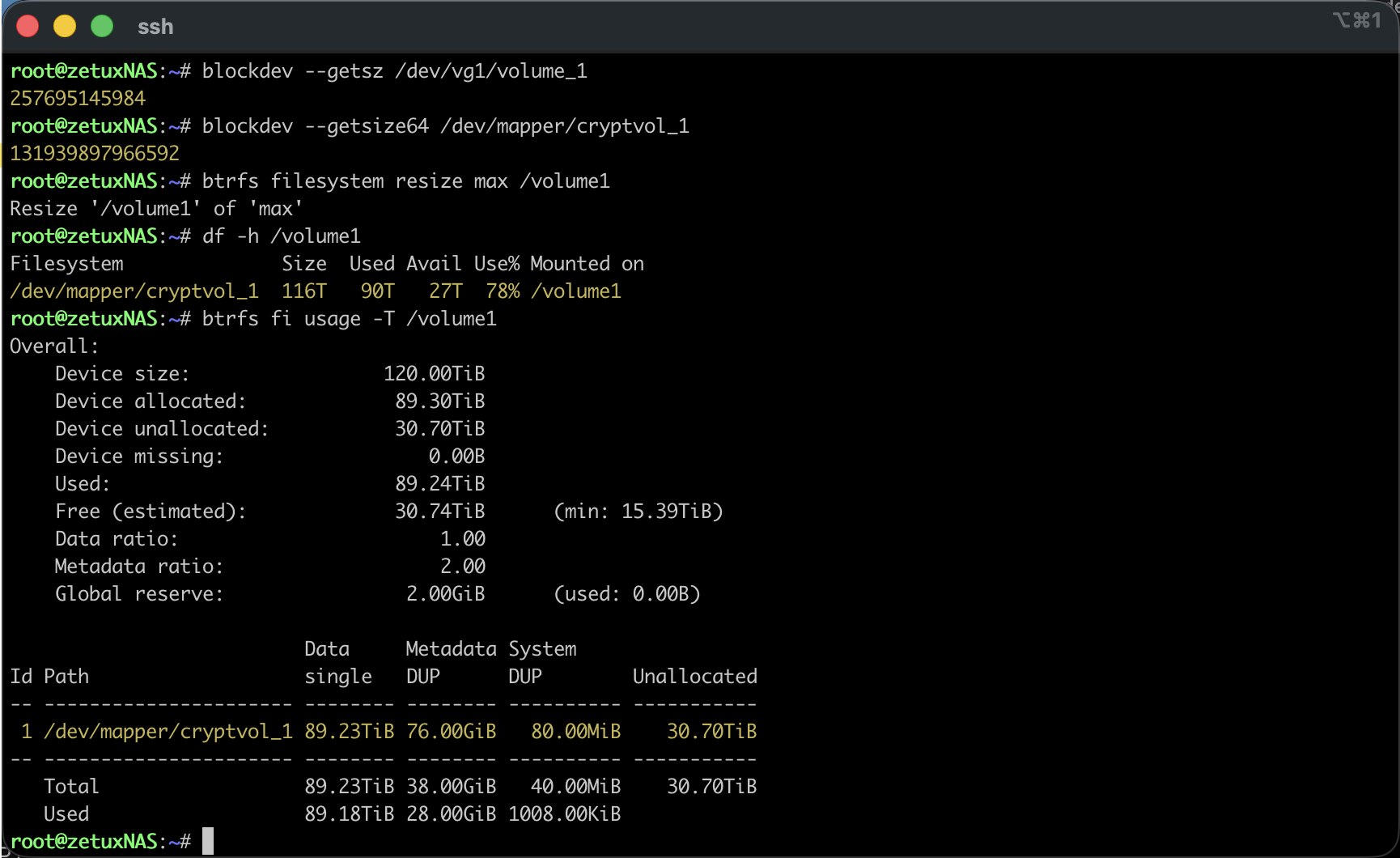
blockdev --getsize64 /dev/mapper/cryptvol_1Resize des Filesystems
Nach dem Reboot oder dem manuellen resize des cachedev_0 sowie anfälligem cryptvol_1, informiere ich jetzt das Btrfs über den zusätzlichen Platz. Das funktioniert online über den Mountpoint. Wer die maximale verfügbare Grösse auch im FS nutzen möchte, nimmt die bequeme Variante:
btrfs filesystem resize max /volume1Alternativ lässt sich eine konkrete Differenz angeben, zum Beispiel +12t. Nach wenigen Augenblicken bestätigt # df -h /volume1 die gewachsene Kapazität, und # btrfs fi usage -T /volume1 zeigt den neuen freien Bereich auf der Ebene der Btrfs-Chunks. Der gesamte Vorgang läuft ohne Unterbrechung der Freigaben.
Je nach Füllstand lohnt sich anschliessend ein leichter Balance-Lauf, der nur stark belegte Chunks anfasst, um die Verteilung zu glätten, ohne das System unnötig zu beschäftigen:
btrfs balance start -dusage=5 -musage=5 /volume1
btrfs balance status /volume1Der Balance-Schritt ist optional; er sorgt dafür, dass zukünftige Allokationen nicht an Altlasten scheitern, z.B. wenn Daten und Metadaten ungleichmässig verteilt sind. Er ist gerade bei sehr grossen Dateisystemen mit langer Historie nützlich, in frischen Setups jedoch oft nicht nötig.

Zurück in der DSM-Oberfläche wird das Volume anschliessend mit der neuen, vollen Grösse angezeigt. Der Dialog «Grösse ändern» wird weiterhin die bekannte Obergrenze als «Max. zuweisbare Grösse» nennen; dies gilt jedoch lediglich für den DSM-Disk-Assistent. Künftige Erweiterungen laufen auf demselben Weg wieder über LVM und btrfs filesystem resize. Wer die Operation kontrolliert begleiten möchte, überwacht parallel # dmesg -w und die Btrfs-Statistiken, während die Änderung greift.
Ein Wort zur Sicherheit gehört in diesen Kontext: Auch wenn der Weg technisch sauber ist, bleibt er von Synology in dieser Form «nicht unterstützt». Für produktive Volumes gilt wie immer, dass ein aktuelles, getestetes Backup Voraussetzung ist. Das Verfahren verändert keine Dateninhalte, aber es operiert an verschiedenen Speicher Schichten, die für alles darüber verantwortlich sind. Wer mehrere Volumes im selben Pool betreibt, vergewissert sich vor dem Extend, dass er das richtige LV erwischt; die eindeutige lv_path-Prüfung vor dem eigentlichen Befehl ist der entscheidende Schutz gegen Vertipper.
Fazit
Der scheinbare Widerspruch zwischen freiem Speicher im Pool und einer starren Grenze beim Volume ist kein Indiz für ein Limit von Btrfs, LVM oder der Hardware und schon gar nicht eine Frage der RAM-Ausstattung. Es ist eine Hersteller- und GUI-seitige Schranke im DSM, die den Disk-Assistent limitiert, nicht die darunter liegende Technologie. Wer das versteht, kann ein bestehendes Volume online und ohne Downtime vergrössern, indem er das Logical Volume per lvextend erweitert und das Btrfs per btrfs filesystem resize nachzieht. Danach steht die Kapazität dort zur Verfügung, wo sie hingehört: im Dateisystem, dort wo die Daten gespeichert werden. Für mich ist das der pragmatischste Weg, mit dem sich grosse Pools auf allen Synology Geräten sinnvoll nutzen lassen, ohne dabei auf die künstliche 108-TiB-Deckelung hereinzufallen.