Die Nutzeraktivitäten innerhalb der eigenen Firma in Form von Logs sind unglaublich wertvolle Daten. Systemausfälle oder Leistungszustände liefern zusätzlich reichhaltige Informationen über die Qualität eines Netzwerks oder eines Produktes. Das händische Sammeln all solcher Aktionen, sowohl von Menschen als auch von Maschinen, ist in den meisten Fällen jedoch eine sehr komplexe Aufgabe.
ELK ist ein Technologiestack, der Elasticsearch, Logstash und Kibana kombiniert, um einen umfassenden Ansatz zur Konsolidierung, Verwaltung und Analyse von Logs und Protokollen aus Ihrer gesamten Firma zu bieten. Es gestattet Echtzeiteinblicke in Netzwerkvorgänge, Firewall Aktivitäten, Domain-Controller Log Daten und führt dabei auch gleich automatisierte und kontinuierliche Sicherheitsanalysen durch.
Sämtliche Events und Log-Daten, zentral sammeln, durchsuchen, automatisiert analysieren, auswerten und Alarme auslösen, sobald Security-Probleme oder unerlaubte Vorgänge erkannt werden.
Das Herzstück – Elasticsearch
Als Hauptkomponente eines ELK-Stack’s kommt Elasticsearch als Herzstück und im produktiven Umfeld in Form eines Clusters zum Einsatz. Es dient als Datenbank, der Speicherort sämtlicher Daten, welche in separaten Log-Indexen, Indices unterteilt werden können. Hier wird das Monitoring-Cluster auch zum Leben erweckt. Sämtliche Speicherung, Suchen, ob automatisiert oder manuell, werden hier via API-Anfragen und einer bilateralen Kommunikation zwischen den Cluster-Member Node’s durchgeführt.
Da Elasticsearch sehr umfangreich ist, veröffentlichen wir unter: Elasticsearch – Die High Performance Search Engine noch einen separaten Post dazu.
Die Normalisierung von Logs durch Logstash
Die Integration von Custom-Systeme, wie sie oft bei grösseren Industrie-Unternehmen wie Gas, Wasser oder auch Strom Unternehmungen vorkommen, setzt oft eine Normalisierung der Logs voraus. Das bedeutet, die Log-Daten, welche von den unterschiedlichen Devices produziert werden, müssen zuerst in ein einheitliches Format überführt werden, dass anschliessend wiederum in das Elasticsearch Cluster importiert werden kann. Dies betrifft vor allem, Technologien, welche nicht bereits durch die offiziellen Data-Shippers wie Filebeat, Winlogbeat, Auditbeat, Metricbeat oder Packetbeat abgedeckt werden.
- Ein Fleet-Server wäre dabei auch eine gute Möglichkeit, Perimeter-Firewalls oder andere Log-Quellen in Elasticsearch zu integrieren.
- Bereits vorhandene Integrationen können unter folgendem Link gefunden werden: Fleet-Agents.
Mit Logstash ist es anhand von selbst erstellten Pipelines und sogenannten GROK-Patterns auch möglich, eigene Log-Files, wie z.B. ein selbst erstelltes Python-Skript, in Searchable Fields zu mappen und in Elasticsearch zu indexieren (speichern in Elasticsearch). Als Beispiel können mit GROK wie auch bei Regex, alle Usernamen oder IP-Adressen aus einem speziellen Logfile selektiert werden und anhand eines Key-Value-Matchings im JSON Format für Elasticsearch vorselektiert werden. Das fertig gemappte Logfile wird am Ende der Pipeline in Elasticsearch importiert.
Das Thema Logstash, sowie das Grundprinzip der Pipelines wird für ein tieferes Verständnis zu einem späteren Zeitpunkt noch in einem eigenen Post veröffentlicht: Logstash – Die Log-Pipeline.
Die Benutzeroberfläche Kibana
Unten sehen Sie einige Screenshots von Kibana aus einem produktiven Einsatz. Kibana wurde früher als eigenständiges Produkt entwickelt, heute stellt es die grafische Oberfläche, also das Web-UI von Elasticsearch dar und würde ohne Elasticsearch auch nicht mehr eigenständig funktionieren.
Am Ende dieses Blog-Eintrags finden Sie zudem noch ein paar Hersteller-Demos, wie die Datenvisualisierung mit Kibana aussehen könnte.

Um Daten in Elasticsearch zu indexieren, gibt es unzählige Wege:
- Beats Data-Shippers
- Filebeat – Alles, was in Form von Log-Files daherkommt, z.B. Apache, Nginx, Linux-Messages, Audit.log, usw.
- Winlogbeat – Sämtliche Windows Eventlog Messages und diverse Erweiterungen, z.B. PowerShell-Eingaben usw.
- Auditbeat – Security-relevante Messages, Login-Versuche, z.B. auf Unix-Systemen
- Packetbeat – Netzwerkaktivitäten, Latenzen oder Netzwerkprobleme
- Logstash
- Syslog – Input, der Netzwerkport ist frei konfigurierbar
- Kafka – Input und Output, der Netzwerkport ist frei konfigurierbar
- RabbitMQ – Input und Output, der Netzwerkport ist frei konfigurierbar
- ⇒ Komplette Liste der Logstash-Inputs
- Fleet-Server
- Sämtliche Integrationen unter folgendem Link: Fleet-Integrationen
Elasticsearch ist eine as-is-Datenbank. Das heisst, dass alle Mappings von Daten und Fields müssen vor dem finalen indexieren erfolgen. Bei Standardprodukten, welche weltweit bekannt sind, z.B. Palo Alto-Firewalls, Cisco-Produkte, Webserver, Windows-Systeme, Linux-System-Logs, braucht es in den meisten Fällen keine zusätzliche Aufbereitung mit GROK, da bei solchen Technologien bereits automatisch alle Felder korrekt zugewiesen werden.
Sollte dies einmal nicht der Fall sein, kann dies straightforward mit Logstash nachgeholt werden, vor allem wenn es sich um eine Eigenentwicklung handeln sollte.
- Mehr über: Wie eine Logstash-Pipeline funktioniert
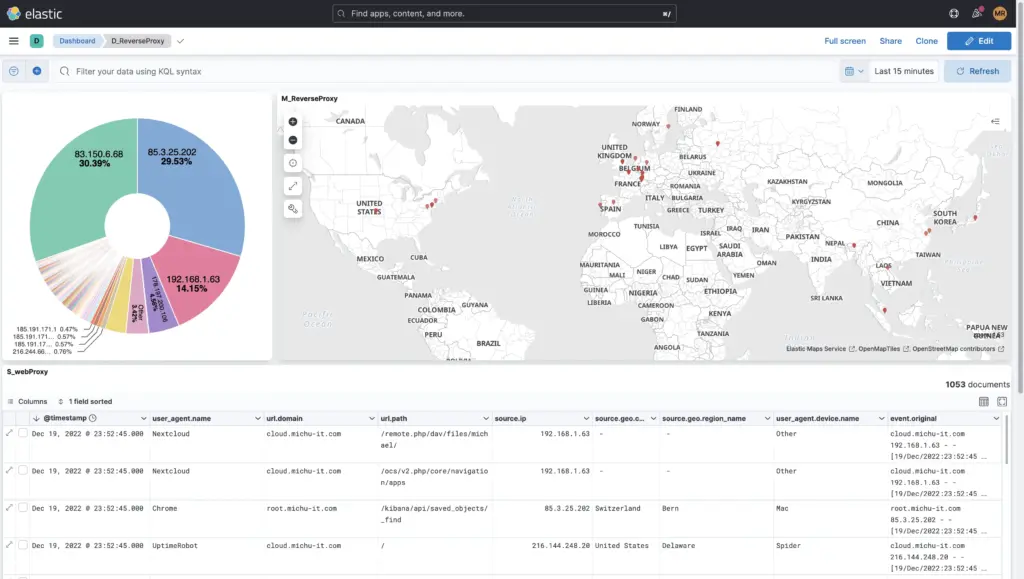
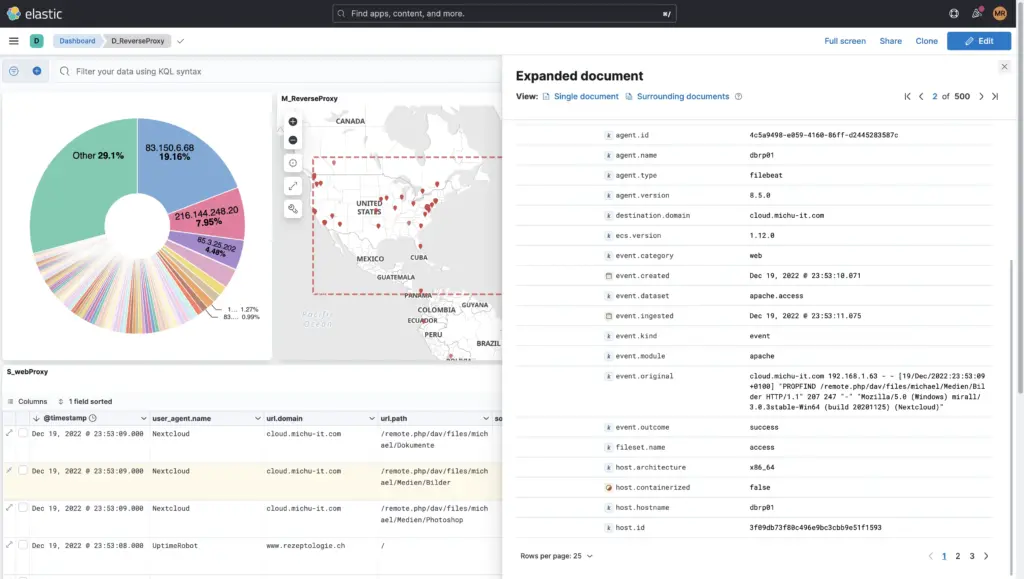
Die Daten oder Logs können im Menu «Discover» analysiert und durchsucht werden.
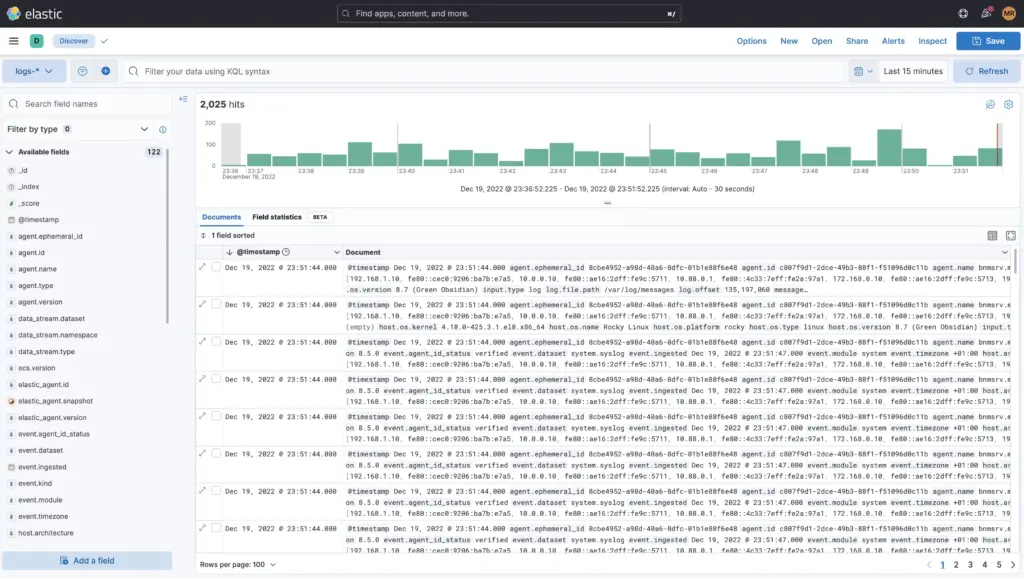
Hier kann per ausschliessen von Eventkategorien oder durch explizites Einschliessen wie die Suche nach dem Tag Access Denied oder 403 und noch vielem mehr gesucht werden. Es kann auch die KQL (Kibana Query Language) gebraucht werden oder für mutige Apache-Lucene.
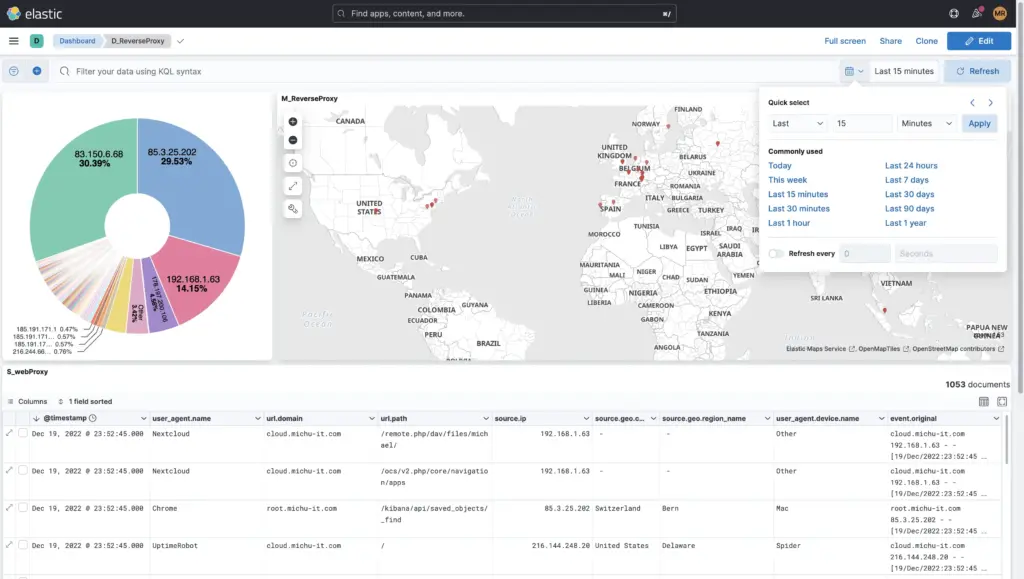
Weiter kann der Zeitraum feingranular eingeschränkt werden oder auch nach einem spezifischen Datum innerhalb eines Zeitraums auf die Millisekunde genau gesucht werden. Auch hier können zusätzliche Filter wie z.B. nur die Logs von der Firewall etc. hinzugefügt werden.
Unter Dashboards finden sich über 40 Default-Dashboards, welche bereits mit Elasticsearch und dessen Beats mitkommen. Diese können angepasst, kopiert und oder unter einem neuen Namen gespeichert werden.
Natürlich können auch eigene Dashboards from-scratch erstellt werden, wie das Beispiel dieses Reverse-Proxies zeigt:
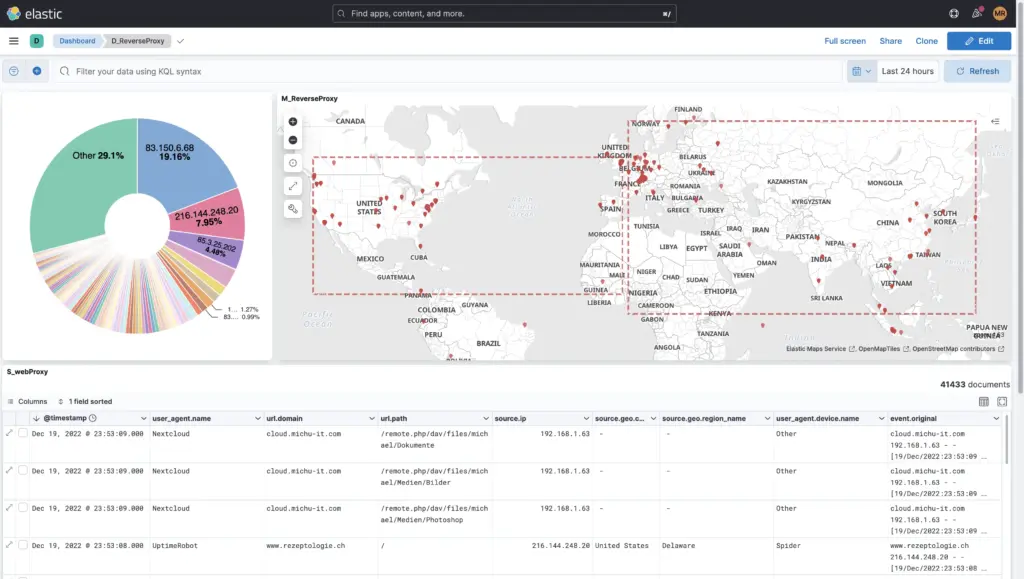
Logs brauchen Speicherplatz. Je nach Firma und Firewalls kann dies pro Tag auch bis zu 150 GB ausmachen. Hier macht es Sinn, dass man sich überlegt, wie lange die Daten durchsuchbar sein sollen und wann diese archiviert oder gar gelöscht werden können. Dazu gibt es vier Lifecycle-Phasen, die einfach in einer Lifecycle-Policy je Index oder global definiert werden können:
- Hot-Phase
- Hier befinden sich die Live-Daten.
- Hier wird indexiert und aktiv gesucht.
- Am performantesten auf lokalem oder sogar SSD-Storage
- Warm-Phase
- Die Warm-Phase ist da, falls man Logs länger durchsuchen möchte, aber diese nach einem gewissen Zeitpunkt auf einen günstigeren Storage auslagern möchte.
- Beispiel: Nach 20 Tagen sollen alle Logs automatisch vom SSD-Storage auf einen NFS-Share gemoved, also auf die Warm-Node’s verschoben werden.
- Diese Logs sind noch aktiv durchsuchbar, wenn eine längere Zeit zurück gesucht wird, z. B. über die letzten 90 Tage (Suche in hot und warm).
- Cold-Phase
- Diese Phase gilt nur zu Archivierungszwecken.
- Es kann nicht mehr aktiv darin gesucht werden. Um die Daten erneut zu durchsuchen, müssten diese zuerst in einen temporären Index reindexiert werden, Use-Case sind Banken, die Logs 10 Jahre aufbewahren möchten.
- Delete-Phase
- Logs, die diese Phase erreichen, werden vom Cluster gelöscht.
Wichtig zu erwähnen: Es müssen nie alle Phasen definiert werden. Es kann auch nur eine Hot-Phase von 30 Tagen geben und danach gleich die Delete-Phase.